
Es gibt inzwischen diverse Initiativen, um die Buchbestände dieser Welt zu scannen und anschliessend online durchsuchbar und lesbar zu machen. Die bekannteste – und umstrittenste – ist die Google Buchsuche, die an der Frankfurter Buchmesse 2004 erstmals vorgestellt wurde. Google offeriert Verlagen (Google Print) und Bibliotheken (Google Library) eine kostenlose Digitalisierung ihrer Verlagsprogramme bzw. Bestände. Die digitalisierten Bücher sind anschliessend über die Google Buchsuche im Volltext durchsuchbar und – je nach Copyright-Situation – auch online lesbar.
Konkurrent Microsoft hat mit Live Search Books Ende 2006 ein ähnliches Programm lanciert (vgl. Berichterstattung bei C-Net), und auch Yahoo! und Amazon befassen sich mit der Digitialisierung von Buchbeständen. Die Angebote der Privatwirtschaft sind für Verlage und Bibliotheken attraktiv, da sie meist beschränkte Mittel haben und den arbeitsintensiven Scan-Prozess nicht selbst finanzieren könnten. Den Verlagen eröffnet sich hier sogar ein neues Marketing-Konzept, denn wer über eine Buchsuche ein copyright-geschütztes Buch findet, muss es normalerweise kaufen, um es lesen zu können. Trotzdem werden die Anstrengungen von Google & Co. auch kritisiert, da auf diese Weise privatwirtschaftliche Unternehmen die faktische Kontrolle über riesige Informationsbestände erhalten, zumal sie für ihre Scan-Dienstleistung eine mehr oder weniger ausgeprägte Exklusivität beanspruchen.
Allein durch die Auswahl der Bücher, die digitalisiert (oder eben nicht digitalisiert) werden, beeinflusst Google das Wissen dieser Welt. So stellt etwa die Konzentration auf englischsprachige Bibliotheken eine Selektion dar, die bereits in Europa Bedenken weckt und in anderen Teilen der Welt sicher noch weit kritischer beurteilt wird. Und auch wenn Google mit seinem inoffiziellen Unternehmensmotto «Don’t be evil» entsprechende Bedenken zu zerstreuen versucht: Sowohl bei der Internet-Suche (Stichwort: China) als auch bei Google Earth (Stichwort: Irak-Krieg) hat Google in der Vergangenheit Informationen gefiltert und damit Zensur ausgeübt – es wäre also naiv, Zensur bei der Google Buchsuche grundsätzlich auszuschliessen.
Konkurrenz erwächst Google nicht nur von Microsoft, Yahoo! und Amazon, sondern auch von Behörden und Institutionen, welche das weltweite Schrifttum nicht einfach der Privatwirtschaft überlassen wollen. Bekannt ist etwa die Kritik von Jean-Noël Jeanneney, dem ehemaligen Direktor der Französischen Nationalbibliothek, der in seinem Buch «Googles Herausforderung» die nordamerikanische Vormachtsstellung beklagte und eine europäische Digitalisierungsinitiative forderte. In Frankreich gibt es mit Gallica schon seit einigen Jahren ein entsprechendes Projekt, die EU macht mit The European Library Schritte in die entsprechende Richtung, und auf globaler Ebene ist die geplante Word Digital Library der UNESCO zu erwähnen (vgl. World Digital Library: Die freie interkulturelle Online-Bibliothek). Daneben gibt es kleinere Projekte wie z.B. Zeno.org.(vgl. Zeno.org: Digitale Bibliothek mit gemeinfreien Büchern).
Als weitere Alternative etabliert sich die 2005 vom Internet Archive und dessen Gründer Brewster Kahle ins Leben gerufene Open Content Alliance (OCA). Diese Allianz konnte mit dem Beitritt des Boston Library Consortium und der Smithsonian Institution kürzlich interessante neue Partner vermelden (vgl. Berichterstattung bei Heise). Die OCA konzentriert sich auf Werke, deren Copyright bereits ausgelaufen ist. Sie macht den Bibliotheken keine Auflagen bezüglich der weiteren Nutzung der digitalisierten Bücher, verrechnet ihnen dafür 10 Cent pro gescannte Seite. Verwirrend ist allerdings, dass sowohl Yahoo! als auch Microsoft der Open Content Alliance angehören und zugleich eigene Digitalisierungsprogramme betreiben.
")
")
")
")
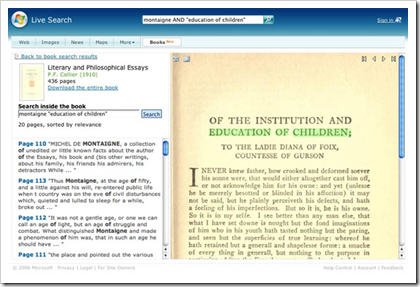
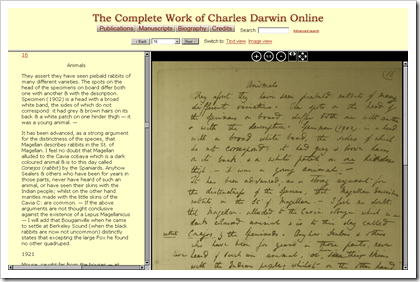
 In der Regel stehen sowohl durchsuchbare Texte als auch Faksimile-Ansichten zur Verfügung. Bei gleichzeitiger Darstellung laufen die beiden Ansichten synchron, was trotz der einigermassen lesbaren Handschrift Darwins eine wertvolle Unterstützung darstellt. Technisch und optisch ist die Website einfach, aber funktional; sie kommt ohne Flash oder andere Technologien aus, welche beim Web-Browser ein Plug-In voraussetzen würde.
In der Regel stehen sowohl durchsuchbare Texte als auch Faksimile-Ansichten zur Verfügung. Bei gleichzeitiger Darstellung laufen die beiden Ansichten synchron, was trotz der einigermassen lesbaren Handschrift Darwins eine wertvolle Unterstützung darstellt. Technisch und optisch ist die Website einfach, aber funktional; sie kommt ohne Flash oder andere Technologien aus, welche beim Web-Browser ein Plug-In voraussetzen würde.
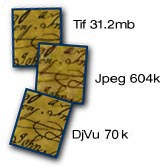 Die gescannten Bitmap-Grafiken werden sehr effizient komprimiert, was im Vergleich zu den klassischen Grafikformaten sehr kleine Dateigrössen ergibt.
Die gescannten Bitmap-Grafiken werden sehr effizient komprimiert, was im Vergleich zu den klassischen Grafikformaten sehr kleine Dateigrössen ergibt.





